Recharch Papers Published from our Project:
আমাদের প্রকল্প থেকে প্রকাশিত রিচার্জ পেপারস:
हमारी परियोजना से प्रकाशित शोध पत्र:
1) Land Use/Land Cover Classification with Spectral Indices and Otsu Thresholding
১) বর্ণালী সূচক এবং ওৎসু থ্রেশহোল্ডিং সহ ভূমি ব্যবহার/ভূমি আচ্ছাদন শ্রেণীবিভাগ
१) स्पेक्ट्रल सूचकांकों और ओत्सु थ्रेशोल्डिंग के साथ भूमि उपयोग/भूमि आवरण वर्गीकरण
Authors: Subhash Mukherjee, Sourav Das, Somnath Mukhopadhyay, Sunita Sarkar, Wangjam Niranjan Singh and Ajoy Kumar Khan.
লেখক: সুভাষ মুখার্জী, সৌরভ দাস, সোমনাথ মুখোপাধ্যায়, সুনিতা সরকার, ওয়াংজাম নিরঞ্জন সিং এবং অজয় কুমার খান।
लेखक: सुभाष मुखर्जी, सौरव दास, सोमनाथ मुखोपाध्याय, सुनीता सरकार, वांगजम निरंजन सिंह और अजॉय कुमार खान।
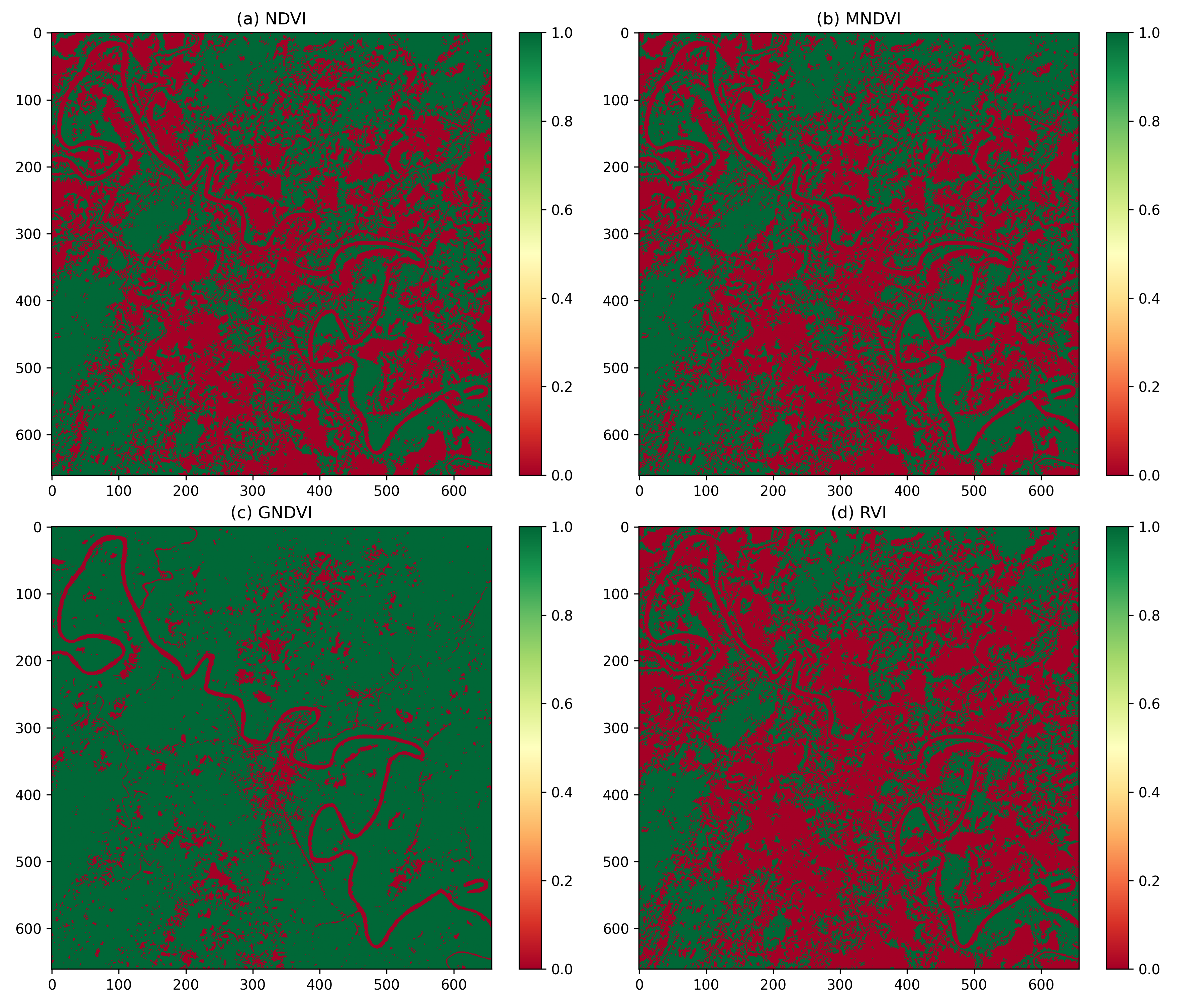
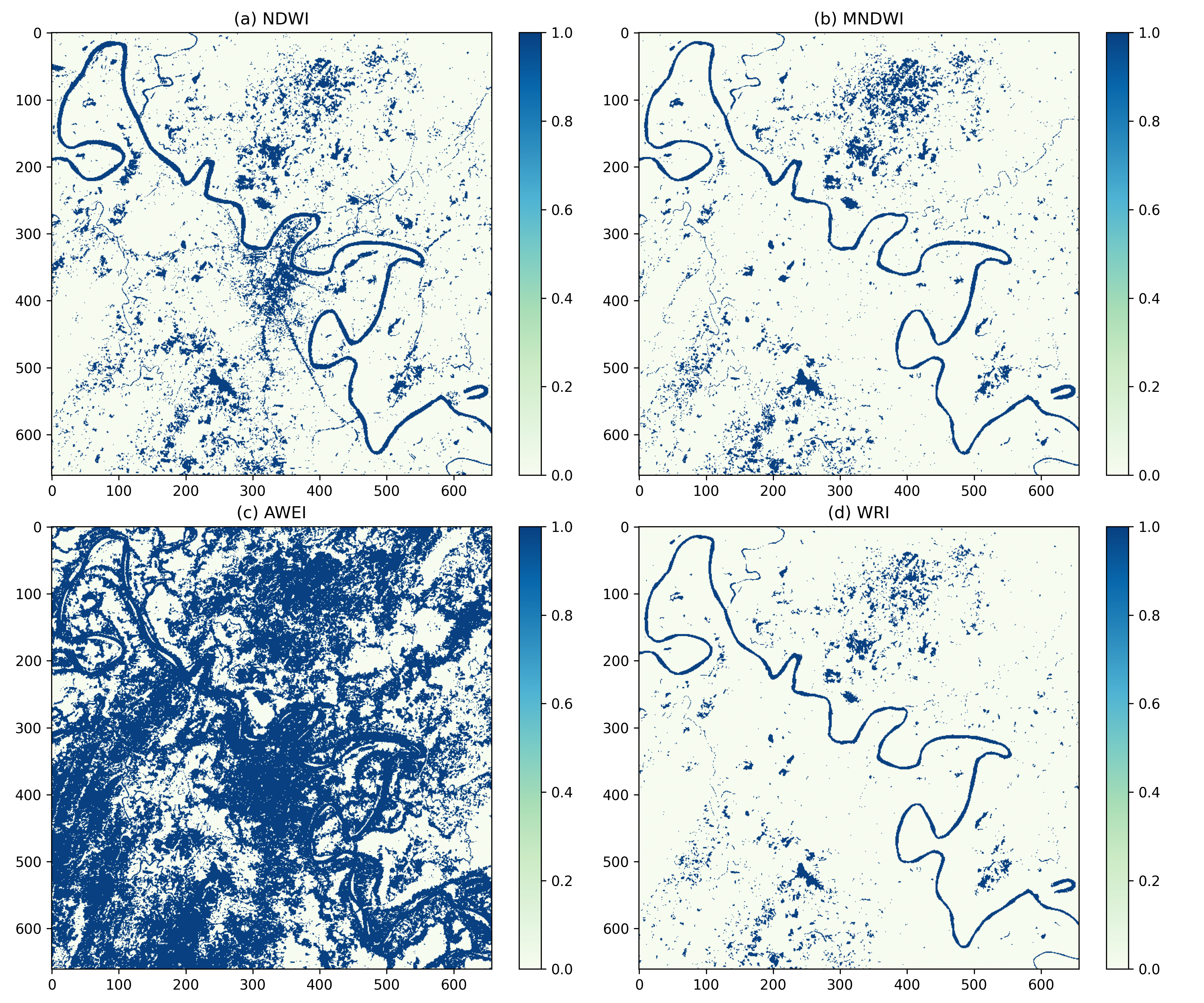
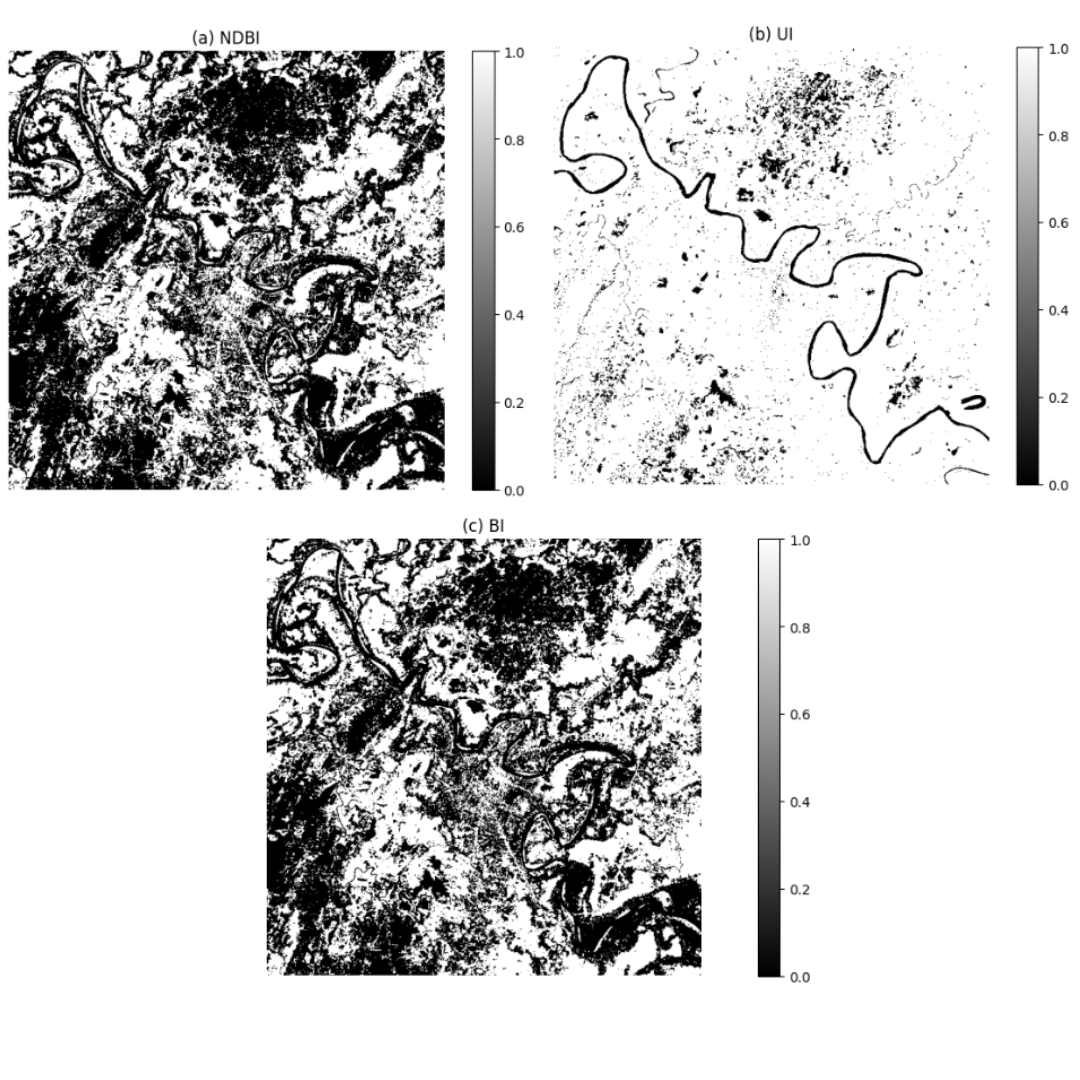
Accurate land use/land cover (LULC) classification is crucial for understanding environmental dynamics, monitoring natural resources, managing urban expansion, and promoting sustainable land management practices. The availability of labeled datasets is a significant obstacle to accurate land use/land cover (LULC) classification in isolated and underrepresented areas like the Barak River Basin. This study presents an unsupervised classification on Landsat 8 satellite imagery, implementing several spectral indices to overcome the insufficiency of the label data set. For vegetation identification, the Normalized Difference Vegetation Index (NDVI), Modified NDVI (MNDVI), Green NDVI (GNDVI), and Ratio Vegetation Index (RVI) were calculated. Water body detection utilized the Normalized Difference Water Index (NDWI), Modified NDWI (MNDWI), Water Ratio Index (WRI), and Automated Extraction of Water Index (AEWI). For built-up area mapping the Normalized Difference Built-up Index (NDBI), Urban Index (UI), and Built-up Index (BI) were evaluated. Amid these, it came to light that NDVI, WRI, and BI performed best for their respective categories. Otsu's thresholding technique was applied to further process these determined indices in order to classify the binary imagery of the Barak River Basin. Notwithstanding the lack of labeled training data, the thereby generated classification output was evaluated through ground truth verification and accuracy assessment, suggesting excellent performance. Utilizing the highest-performing indices, we were able to generate the label Landsat 8 imagery using an unsupervised method. In areas with inadequate information, this technique makes it possible to develop spatiotemporal datasets for long-term environmental monitoring and land management, and it determines the prerequisites for scalable LULC mapping.
সঠিক ভূমি ব্যবহার/ভূমি আচ্ছাদন (LULC) শ্রেণীবিন্যাস পরিবেশগত গতিশীলতা বোঝা, প্রাকৃতিক সম্পদ পর্যবেক্ষণ, নগর সম্প্রসারণ পরিচালনা এবং টেকসই ভূমি ব্যবস্থাপনা চর্চা প্রচারের জন্য অত্যন্ত গুরুত্বপূর্ণ। লেবেলযুক্ত ডেটাসেটের প্রাপ্যতা বিচ্ছিন্ন এবং কম প্রতিনিধিত্বকারী অঞ্চল যেমন বরাক নদী অববাহিকায় সঠিক ভূমি ব্যবহার/ভূমি আচ্ছাদন (LULC) শ্রেণীবিন্যাসের একটি গুরুত্বপূর্ণ প্রতিবন্ধক। এই গবেষণায় Landsat 8 স্যাটেলাইট ইমেজারির উপর একটি অযাচাইকৃত শ্রেণীবিন্যাস উপস্থাপন করা হয়েছে, যেখানে লেবেল ডেটাসেটের ঘাটতি কাটিয়ে ওঠার জন্য একাধিক স্পেকট্রাল সূচক ব্যবহার করা হয়েছে। উদ্ভিদ সনাক্তকরণের জন্য Normalized Difference Vegetation Index (NDVI), Modified NDVI (MNDVI), Green NDVI (GNDVI), এবং Ratio Vegetation Index (RVI) গণনা করা হয়েছে। জলাশয় সনাক্তকরণের জন্য Normalized Difference Water Index (NDWI), Modified NDWI (MNDWI), Water Ratio Index (WRI), এবং Automated Extraction of Water Index (AEWI) ব্যবহার করা হয়েছে। নির্মিত এলাকার মানচিত্রায়নের জন্য Normalized Difference Built-up Index (NDBI), Urban Index (UI), এবং Built-up Index (BI) মূল্যায়ন করা হয়েছে। এর মধ্যে দেখা গেছে যে NDVI, WRI, এবং BI তাদের নিজ নিজ শ্রেণীর জন্য সর্বোত্তম কাজ করেছে। বরাক নদী অববাহিকার বাইনারি ইমেজারি শ্রেণীবদ্ধ করার জন্য এই নির্ধারিত সূচকগুলিকে আরও প্রক্রিয়াকরণের জন্য Otsu's thresholding technique প্রয়োগ করা হয়েছে। লেবেলযুক্ত প্রশিক্ষণ ডেটার অভাব সত্ত্বেও, উৎপন্ন শ্রেণীবিন্যাস আউটপুট মাটির সত্যতা যাচাই এবং যথার্থতা মূল্যায়নের মাধ্যমে মূল্যায়ন করা হয়েছে, যা চমৎকার কার্যকারিতা নির্দেশ করে। সর্বোচ্চ কার্যকর সূচকগুলি ব্যবহার করে, আমরা একটি অযাচাইকৃত পদ্ধতি ব্যবহার করে লেবেল Landsat 8 ইমেজারি তৈরি করতে সক্ষম হয়েছি। যেখানে পর্যাপ্ত তথ্য নেই, এই প্রযুক্তি দীর্ঘমেয়াদী পরিবেশগত পর্যবেক্ষণ এবং ভূমি ব্যবস্থাপনার জন্য স্থানিক-কালিক ডেটাসেট তৈরি করা সম্ভব করে এবং এটি স্কেলযোগ্য LULC ম্যাপিংয়ের জন্য প্রয়োজনীয় শর্ত নির্ধারণ করে।
सटीक भूमि उपयोग/भूमि आवरण (LULC) वर्गीकरण पर्यावरणीय गतिशीलता को समझने, प्राकृतिक संसाधनों की निगरानी करने, शहरी विस्तार का प्रबंधन करने और सतत भूमि प्रबंधन प्रथाओं को बढ़ावा देने के लिए अत्यंत महत्वपूर्ण है। लेबल किए गए डेटासेट की उपलब्धता, बराक नदी घाटी जैसे पृथक और कम प्रतिनिधित्व वाले क्षेत्रों में सटीक भूमि उपयोग/भूमि आवरण (LULC) वर्गीकरण के लिए एक प्रमुख बाधा है। इस अध्ययन में Landsat 8 उपग्रह इमेजरी पर एक असUPरवाइज्ड वर्गीकरण प्रस्तुत किया गया है, जिसमें लेबल डेटा सेट की कमी को दूर करने के लिए कई स्पेक्ट्रल इंडेक्स लागू किए गए हैं। वनस्पति पहचान के लिए Normalized Difference Vegetation Index (NDVI), Modified NDVI (MNDVI), Green NDVI (GNDVI), और Ratio Vegetation Index (RVI) की गणना की गई। जल निकाय का पता लगाने के लिए Normalized Difference Water Index (NDWI), Modified NDWI (MNDWI), Water Ratio Index (WRI), और Automated Extraction of Water Index (AEWI) का उपयोग किया गया। निर्मित क्षेत्र के मानचित्रण के लिए Normalized Difference Built-up Index (NDBI), Urban Index (UI), और Built-up Index (BI) का मूल्यांकन किया गया। इनमें से NDVI, WRI, और BI अपने-अपने वर्गों के लिए सर्वश्रेष्ठ प्रदर्शन करते पाए गए। बराक नदी घाटी की बाइनरी इमेजरी को वर्गीकृत करने के लिए इन निर्धारित इंडेक्स को और प्रोसेस करने हेतु Otsu's thresholding तकनीक लागू की गई। लेबल किए गए प्रशिक्षण डेटा की अनुपलब्धता के बावजूद, इस प्रकार उत्पन्न वर्गीकरण आउटपुट का ग्राउंड ट्रुथ वेरिफिकेशन और एक्यूरेसी असेसमेंट द्वारा मूल्यांकन किया गया, जिससे उत्कृष्ट प्रदर्शन का संकेत मिला। सर्वाधिक प्रदर्शन करने वाले इंडेक्स का उपयोग करके, हमने असUPरवाइज्ड विधि से लेबल Landsat 8 इमेजरी उत्पन्न की। अपर्याप्त जानकारी वाले क्षेत्रों में, यह तकनीक दीर्घकालिक पर्यावरण निगरानी और भूमि प्रबंधन के लिए स्थानिक-कालिक डेटासेट विकसित करना संभव बनाती है और यह स्केलेबल LULC मैपिंग के लिए आवश्यक शर्तों को निर्धारित करती है।
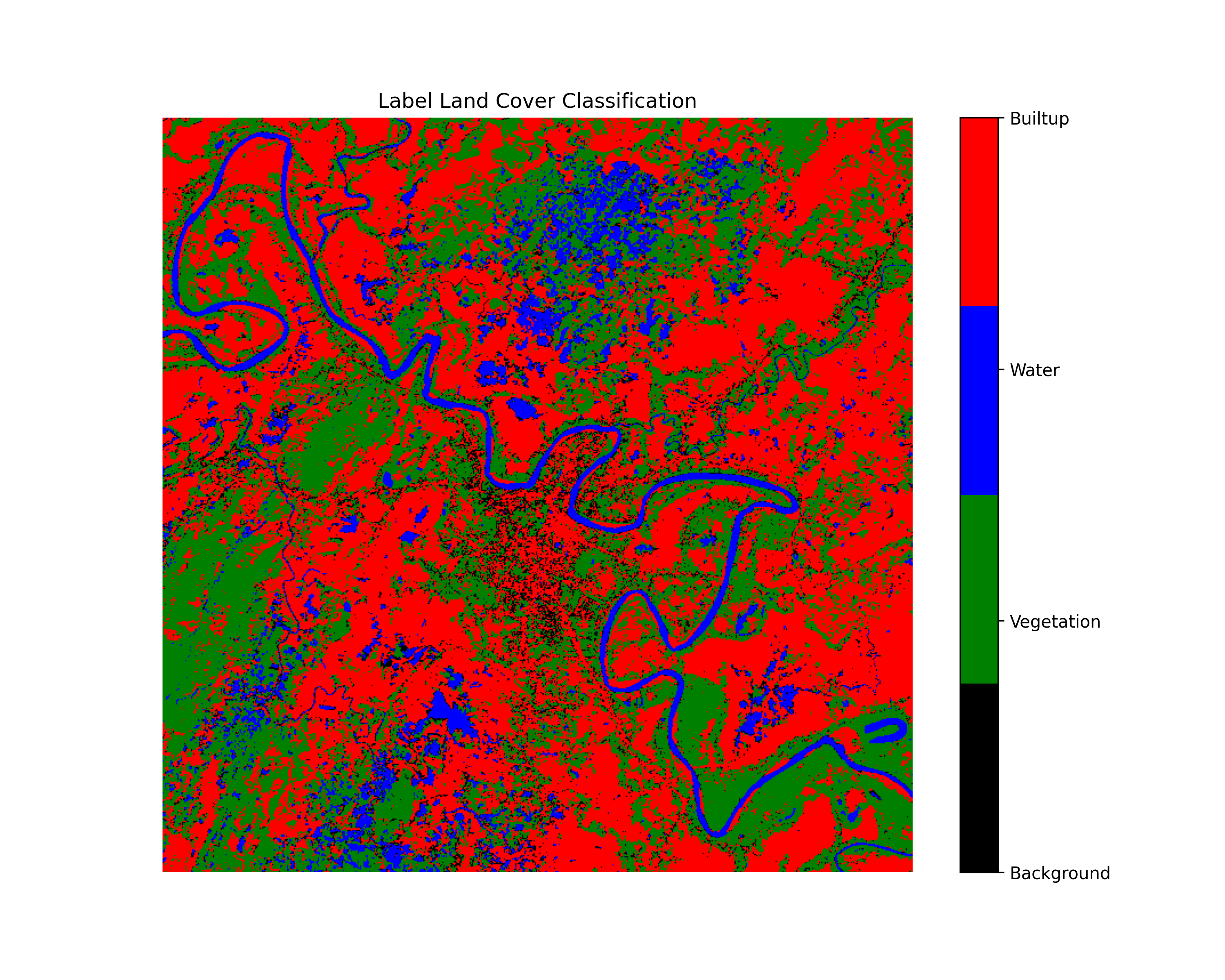
In our study NDVI, WRI, and BI proved to be the most effective indices in their respective categories. Utilizing those indices we are able to generate the final unsupervised label data shown in Figure 7. Where the red color shows the built-up area, blue color resembles all types of water bodies, green shows the vegetation area and lastly black incorporates the background.In conclusion, by implementing NDVI, WRI and BI we are able to label the data using this unsupervised proposed methodology.
আমাদের গবেষণায় NDVI, WRI, এবং BI তাদের নিজ নিজ শ্রেণীতে সবচেয়ে কার্যকর সূচক হিসেবে প্রমাণিত হয়েছে। এই সূচকগুলি ব্যবহার করে আমরা চূড়ান্ত অযাচাইকৃত লেবেল ডেটা তৈরি করতে সক্ষম হয়েছি যা চিত্র ৭-এ দেখানো হয়েছে। যেখানে লাল রঙ নির্মিত এলাকা দেখায়, নীল রঙ সমস্ত ধরণের জলাশয়কে বোঝায়, সবুজ রঙ উদ্ভিদের এলাকা নির্দেশ করে এবং সর্বশেষে কালো রঙ ব্যাকগ্রাউন্ডকে অন্তর্ভুক্ত করে। উপসংহারে, NDVI, WRI এবং BI প্রয়োগ করে আমরা এই অযাচাইকৃত প্রস্তাবিত পদ্ধতি ব্যবহার করে ডেটা লেবেল করতে সক্ষম হয়েছি।
हमारे अध्ययन में NDVI, WRI, और BI अपने-अपने वर्गों में सबसे प्रभावी इंडेक्स साबित हुए। इन इंडेक्स का उपयोग करके हम अंतिम असUPरवाइज्ड लेबल डेटा उत्पन्न करने में सक्षम हुए, जो चित्र 7 में दिखाया गया है। जहाँ लाल रंग निर्मित क्षेत्र को दर्शाता है, नीला रंग सभी प्रकार के जल निकायों को दर्शाता है, हरा रंग वनस्पति क्षेत्र को दर्शाता है और अंत में काला रंग बैकग्राउंड को शामिल करता है। निष्कर्षतः, NDVI, WRI और BI को लागू करके हम इस असUPरवाइज्ड प्रस्तावित पद्धति का उपयोग करके डेटा को लेबल करने में सक्षम हुए।
Full Recharch Paper Link:
সম্পূর্ণ রিচার্জ পেপার লিঙ্ক:
पूर्ण रिचार्ज पेपर लिंक:
Documentদলিলदस्तावेज़
2) An Unsupervised-to-Supervised Framework for Vegetation Mapping Using Spectral Indices
২) বর্ণালী সূচক ব্যবহার করে উদ্ভিদ মানচিত্রণের জন্য একটি অযাচাইকৃত-থেকে-যাচাইকৃত কাঠামো
२) स्पेक्ट्रल सूचकांकों का उपयोग करके वनस्पति मानचित्रण के लिए एक असUPरवाइज्ड-से-सUPरवाइज्ड ढांचा
Authors: Bishal Banik, Subhash Mukherjee, Somnath Mukhopadhyay, Sunita Sarkar and Wangjam Niranjan Singh.
লেখক:বিশাল ব্যাংকার, সুভাষ মুখার্জী, সোমনাথ মুখোপাধ্যায়, সুনিতা সরকার এবং ওয়াংজাম নিরঞ্জন সিং।
लेखक: महान व्यापारी, सुभाष मुखर्जी, सोमनाथ मुखोपाध्याय, सुनीता सरकार और वांगजम निरंजन सिंह।
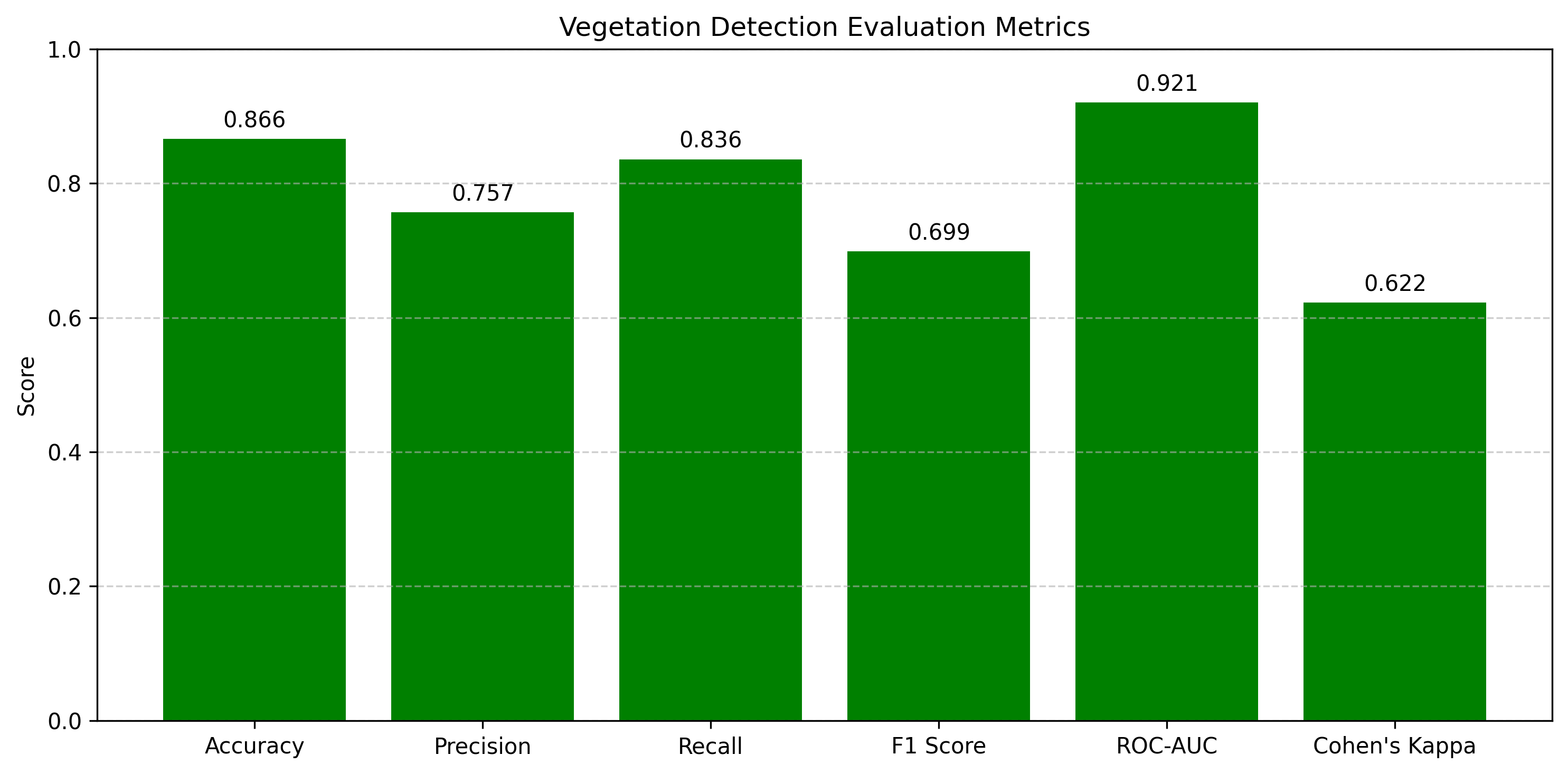
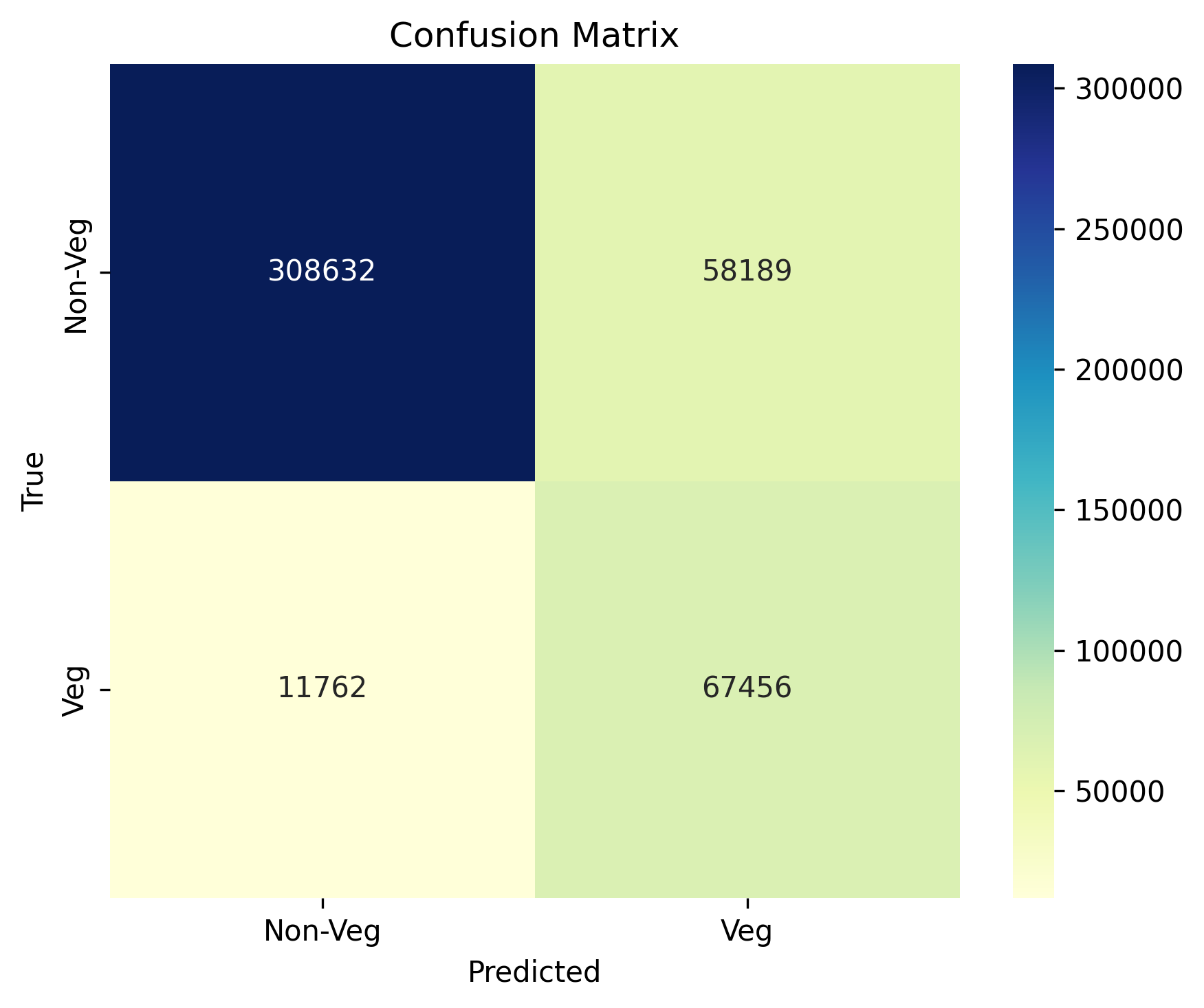
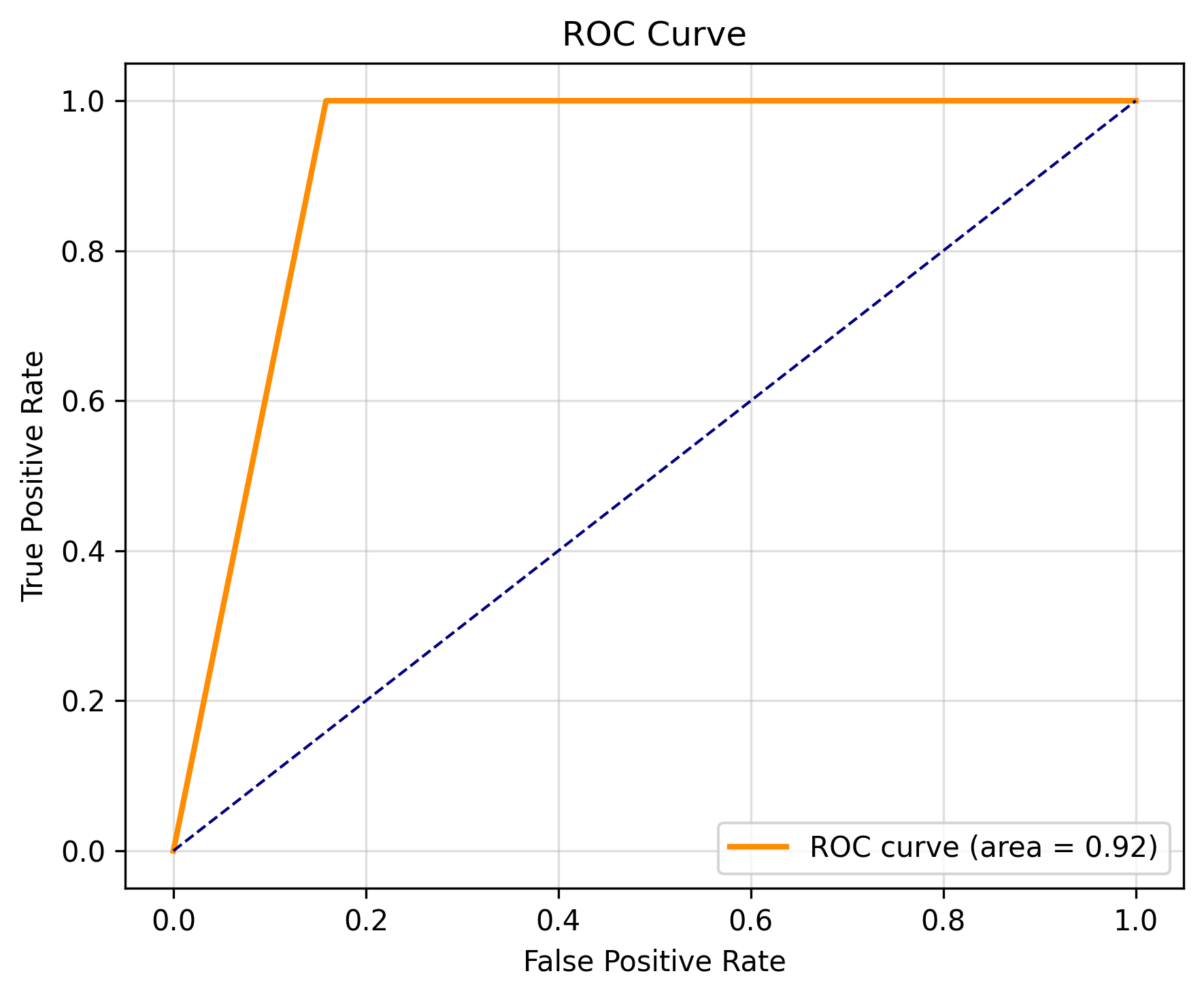
Vegetation detection from satellite imagery is essential for ecological monitoring, agricultural planning, and land use analysis. Traditional supervised methods often demand extensive labeled datasets, which are time-consuming to prepare. This study presents a hybrid unsupervised-to-supervised framework for vegetation detection using unlabelled multispectral satellite imagery. Initially, vegetation pixels are labelled using NDVI thresholding, while water regions are excluded via NDWI-based masking. These selected pixels undergo dimensionality reduction using Principal Component Analysis (PCA) and are clustered using k-means++. The clustered pixels with the highest NDVI mean are labelled as vegetation, forming labels used to train a Random Forest classifier. The trained model then classifies the entire image, producing a refined vegetation map by reapplying NDWI to exclude riverine areas. Validation through Precision, Recall, F1 Score, Accuracy, AUC-ROC, Confusion matrix, Davies–Bouldin Score, and Dunn Index confirms effective clustering, and visual outputs highlight the framework’s reliability. This method offers a scalable, label-free approach that provides an interpretable and efficient solution for vegetation mapping in complex landscapes.
স্যাটেলাইট ইমেজারি থেকে উদ্ভিদ সনাক্তকরণ পরিবেশগত পর্যবেক্ষণ, কৃষি পরিকল্পনা এবং ভূমি ব্যবহার বিশ্লেষণের জন্য অপরিহার্য। প্রচলিত সুপারভাইজড পদ্ধতিগুলি প্রায়ই বিস্তৃত লেবেলযুক্ত ডেটাসেটের প্রয়োজন করে, যা প্রস্তুত করতে সময়সাপেক্ষ। এই গবেষণায় অচিহ্নিত বহুবর্ণালী স্যাটেলাইট ইমেজারি ব্যবহার করে উদ্ভিদ সনাক্তকরণের জন্য একটি হাইব্রিড আনসুপারভাইজড-টু-সুপারভাইজড ফ্রেমওয়ার্ক উপস্থাপন করা হয়েছে। প্রাথমিকভাবে, NDVI থ্রেশহোল্ডিং ব্যবহার করে উদ্ভিদের পিক্সেল লেবেল করা হয়, যেখানে NDWI-ভিত্তিক মাস্কিং এর মাধ্যমে জলাশয় অঞ্চল বাদ দেওয়া হয়। নির্বাচিত পিক্সেলগুলো Principal Component Analysis (PCA) ব্যবহার করে মাত্রা হ্রাসের মধ্য দিয়ে যায় এবং k-means++ ব্যবহার করে ক্লাস্টার করা হয়। সর্বোচ্চ NDVI গড় সহ ক্লাস্টার করা পিক্সেলগুলো উদ্ভিদ হিসেবে লেবেল করা হয়, যা Random Forest classifier প্রশিক্ষণের জন্য লেবেল তৈরি করে। প্রশিক্ষিত মডেলটি পরে পুরো ছবিটি শ্রেণীবদ্ধ করে, NDWI পুনরায় প্রয়োগ করে নদী অঞ্চলগুলো বাদ দিয়ে একটি উন্নত উদ্ভিদ মানচিত্র তৈরি করে। Precision, Recall, F1 Score, Accuracy, AUC-ROC, Confusion matrix, Davies–Bouldin Score এবং Dunn Index এর মাধ্যমে যাচাইকরণ কার্যকর ক্লাস্টারিং নিশ্চিত করে এবং ভিজ্যুয়াল আউটপুট ফ্রেমওয়ার্কটির নির্ভরযোগ্যতা তুলে ধরে। এই পদ্ধতি একটি স্কেলযোগ্য, লেবেল-মুক্ত পন্থা প্রদান করে যা জটিল ভূদৃশ্যে উদ্ভিদ মানচিত্রায়ণের জন্য একটি ব্যাখ্যাযোগ্য এবং দক্ষ সমাধান সরবরাহ করে।
उपग्रह चित्रों से वनस्पति का पता लगाना पारिस्थितिक निगरानी, कृषि योजना और भूमि उपयोग विश्लेषण के लिए आवश्यक है। पारंपरिक सुपर्वाइज़्ड विधियाँ अक्सर बड़े लेबलयुक्त डाटासेट की माँग करती हैं, जिन्हें तैयार करने में समय लगता है। यह अध्ययन बिना लेबल वाले बहु-स्पेक्ट्रल उपग्रह चित्रों का उपयोग करके वनस्पति पहचान के लिए एक हाइब्रिड अनसुपर्वाइज़्ड-टू-सुपर्वाइज़्ड ढाँचा प्रस्तुत करता है। प्रारंभ में, NDVI थ्रेशोल्डिंग का उपयोग करके वनस्पति पिक्सल्स को लेबल किया जाता है, जबकि NDWI-आधारित मास्किंग द्वारा जल क्षेत्रों को बाहर किया जाता है। इन चयनित पिक्सल्स को Principal Component Analysis (PCA) द्वारा आयाम में कमी के लिए प्रोसेस किया जाता है और k-means++ का उपयोग करके क्लस्टर किया जाता है। सबसे अधिक NDVI औसत वाले क्लस्टर्ड पिक्सल्स को वनस्पति के रूप में लेबल किया जाता है, और इन्हीं लेबल्स का उपयोग करके Random Forest classifier को प्रशिक्षित किया जाता है। प्रशिक्षित मॉडल फिर पूरी छवि को वर्गीकृत करता है, NDWI को पुनः लागू करके नदीय क्षेत्रों को बाहर करता है और एक परिष्कृत वनस्पति मानचित्र उत्पन्न करता है। Precision, Recall, F1 Score, Accuracy, AUC-ROC, Confusion matrix, Davies–Bouldin Score और Dunn Index के माध्यम से वैधता जाँच से प्रभावी क्लस्टरिंग की पुष्टि होती है और दृश्य परिणाम ढाँचे की विश्वसनीयता दर्शाते हैं। यह विधि एक स्केलेबल, लेबल-फ्री दृष्टिकोण प्रदान करती है, जो जटिल परिदृश्यों में वनस्पति मानचित्रण के लिए एक व्याख्यायोग्य और कुशल समाधान उपलब्ध कराती है।
This study proposes an efficient hybrid approach for vegetation detection by combining unsupervised k-means++ clustering with Random Forest classification. NDVI and NDWI indices are used to distinguish between vegetation and water regions in order to enhance discrimination near river bodies. PCA is used to reduce the dimensionality of the multispectral imagery, and k-means++ is applied for clustering. Also, the clustering quality is validated by validation metrics DB and Dunn. The results are used to train the RF model, and the classification results accuracy is validated by several validation metrics such as accuracy, precision, F1 score, recall, kappa score, ROC-AUC, and confusion matrix.
The proposed framework suggests a robust and label-free method for vegetation detection. In the future, we will add different machine learning and deep learning models for better clustering and classification.
এই গবেষণায় উদ্ভিদ সনাক্তকরণের জন্য একটি দক্ষ হাইব্রিড পদ্ধতি প্রস্তাব করা হয়েছে, যেখানে আনসুপারভাইজড k-means++ ক্লাস্টারিং এবং Random Forest শ্রেণীবিন্যাসকে একত্রিত করা হয়েছে। NDVI এবং NDWI সূচকগুলি ব্যবহার করা হয়েছে উদ্ভিদ এবং জল অঞ্চলের মধ্যে পার্থক্য করতে, বিশেষ করে নদীর কাছাকাছি অঞ্চলে পার্থক্য উন্নত করার জন্য। PCA ব্যবহার করা হয়েছে বহুবর্ণালী চিত্রের মাত্রা হ্রাস করতে, এবং ক্লাস্টারিংয়ের জন্য k-means++ প্রয়োগ করা হয়েছে। ক্লাস্টারিং গুণমান যাচাই করা হয়েছে DB এবং Dunn সূচকের মাধ্যমে। ফলাফলগুলি RF মডেল প্রশিক্ষণে ব্যবহার করা হয়েছে, এবং শ্রেণীবিন্যাসের যথার্থতা যাচাই করা হয়েছে Accuracy, Precision, F1 Score, Recall, Kappa Score, ROC-AUC এবং Confusion Matrix এর মতো বিভিন্ন সূচক ব্যবহার করে।
প্রস্তাবিত ফ্রেমওয়ার্কটি একটি শক্তিশালী এবং লেবেল-মুক্ত পদ্ধতি প্রদান করে উদ্ভিদ সনাক্তকরণের জন্য। ভবিষ্যতে, আমরা আরও ভালো ক্লাস্টারিং এবং শ্রেণীবিন্যাসের জন্য বিভিন্ন মেশিন লার্নিং এবং ডিপ লার্নিং মডেল যুক্ত করব।
इस अध्ययन में वनस्पति पहचान के लिए एक कुशल हाइब्रिड दृष्टिकोण प्रस्तावित किया गया है, जिसमें अनसुपर्वाइज़्ड k-means++ क्लस्टरिंग को Random Forest वर्गीकरण के साथ संयोजित किया गया है। NDVI और NDWI सूचकांकों का उपयोग वनस्पति और जल क्षेत्रों को अलग करने के लिए किया गया है, ताकि नदी के पास बेहतर भेदभाव किया जा सके। PCA का उपयोग बहु-स्पेक्ट्रल चित्रों के आयाम को कम करने के लिए किया गया है और क्लस्टरिंग के लिए k-means++ लागू किया गया है। क्लस्टरिंग की गुणवत्ता को DB और Dunn सूचकों द्वारा सत्यापित किया गया है। परिणामों का उपयोग RF मॉडल को प्रशिक्षित करने के लिए किया गया है और वर्गीकरण की सटीकता को Accuracy, Precision, F1 Score, Recall, Kappa Score, ROC-AUC और Confusion Matrix जैसे कई मीट्रिक्स द्वारा सत्यापित किया गया है।
प्रस्तावित ढाँचा वनस्पति पहचान के लिए एक मजबूत और लेबल-फ्री विधि प्रस्तुत करता है। भविष्य में, हम बेहतर क्लस्टरिंग और वर्गीकरण के लिए विभिन्न मशीन लर्निंग और डीप लर्निंग मॉडल जोड़ेंगे।
Full Recharch Paper Link:
সম্পূর্ণ রিচার্জ পেপার লিঙ্ক:
पूर्ण रिचार्ज पेपर लिंक:
Documentদলিলदस्तावेज़